Parquet
Goal
Parquet is built:
- from ground up with complex nested data in mind.
- for efficient compression and encoding.
- for everyone.
Benefits for using Parquet
Parquet has the benefits of columnar data source.
- Free and open source. - Open to any project in the Hadoop ecosystem. hadoop
- Language agnostic.
- Used for analytics (OLAP) use cases, typically in conjunction with traditional OLTP databases.
- Supports complex data, big data, and nested data - since Parquet is built from ground up using record shredding and assembly algorithm, with all complex nested data in mind - using this algorithm is superior to simply flattening nested name spaces.
- Particularly efficient in compression and encoding.

File Format
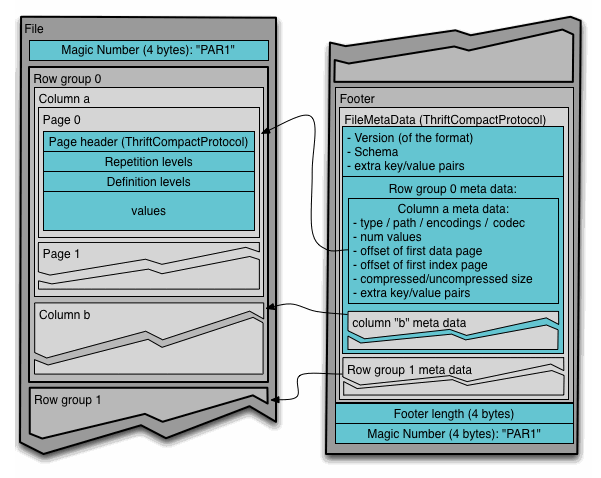
Concepts
- Block is a block in hdfs, on which file is designed.
- File must include the metadata, that is, one or more row groups.
- Row group is merely logical, each row group contains exactly one column chunk per column.
- Column chunk is a chunk of data for a particular column. They are physically contiguous on the disk.
- Page are divisions of column chunks.
Parallelism can be at level of:
- MapReduce - File/Row Group
- IO - Column chunk
- Encoding/Compression - Page

Type
BOOLEAN: 1 bit boolean
INT32: 32 bit signed ints
INT64: 64 bit signed ints
INT96: 96 bit signed ints
FLOAT: IEEE 32-bit floating point values
DOUBLE: IEEE 64-bit floating point values
BYTE_ARRAY: arbitrarily long byte arrays.
Logical types can be built based on the primitive types. For example, string as Byte Array with UTF8 annotation.
Data Pages
dremel encoding with definition and repetition levels.
Inside the page, definition levels data, repetition levels data and encoded values are included. If the data is not nested. i.e. the path depth to the column is 1, only values themselves are required.
The compression and encoding is specified in the page metadata.
See Dremel Paper for detailed explanation.
Modules
- parquet-mr core components of Parquet, provide hadoop IO formats, Pig loaders, and other Java-based utilities
- parquet-cpp and parquet-rs to read-write Parquet files in C++ or Rust.
- Parquet and Pandas DataFrame Looks like when reading parquet files in Pandas, always read into the memory first.